Two-Phase Commit: Coordinating a Distributed Decision
Series: System Design · Distributed Systems — Pillar 8 of 8
Systems Design
| # | Post | What it covers |
|---|---|---|
| 00 | Distributed Systems: What Happens When Machines Disagree | Twenty concepts covering network partitions, consensus, clocks, distributed transactions, CDC, erasure coding, and observability. The final pillar. |
| 01 | Network Partitions: The Failure Mode You Can't Design Away | Network partitions are inevitable. Learn what happens when nodes can't communicate, how systems choose between availability and consistency, and what that means in practice. |
| 02 | Split-Brain: When Two Nodes Both Think They're the Leader | Split-brain occurs when two nodes both believe they're the primary. Learn how it happens, why it causes data corruption, and how STONITH and fencing prevent it. |
| 03 | Heartbeats: How Nodes Know Their Peers Are Alive | Heartbeats let nodes detect peer failures. Learn how timeouts, phi accrual failure detectors, and the tradeoff between false positives and detection speed work. |
| 04 | Leader Election: Agreeing on Who's in Charge | Leader election coordinates which node acts as primary. Learn the bully algorithm, Raft-based election, and why exactly-one-leader guarantees are hard to achieve. |
| 05 | Consensus Algorithms: Agreeing on a Value Across Failures | Consensus lets distributed nodes agree on a value despite failures. Learn what FLP impossibility means, what Paxos and Raft provide, and where consensus is used. |
| 06 | Quorum: How Many Nodes Must Agree? | Quorum determines how many nodes must agree for an operation to succeed. Learn how R + W > N ensures consistency in distributed databases like Cassandra and DynamoDB. |
| 07 | Paxos: The Algorithm That Started It All | Paxos is the foundational distributed consensus algorithm. Learn how its two phases work, why it's hard to implement, and what systems use it in production. |
| 08 | Raft: Consensus Made Understandable | Raft makes distributed consensus understandable. Learn how leader election, log replication, and safety work in the algorithm that powers etcd, CockroachDB, and TiKV. |
| 09 | Gossip Protocol: Decentralised Cluster Communication | Gossip protocols propagate information across a cluster without a central coordinator. Learn how epidemic spreading works and where it's used in production. |
| 10 | Logical Clocks: When Physical Time Isn't Enough | Physical clocks drift and can't establish event order in distributed systems. Logical clocks track causality instead. Learn why this matters and how it works. |
| 11 | Lamport Timestamps: Ordering Events Without a Global Clock | Lamport timestamps assign logical counters to events to establish causal order in distributed systems. Learn how they work and what they can and can't tell you. |
| 12 | Vector Clocks: Knowing When Events Are Truly Concurrent | Vector clocks detect causality and concurrency in distributed systems. Learn how they work, how Dynamo uses them for conflict detection, and their limitations. |
| 13 | Distributed Transactions: When One Machine Isn't Enough | Distributed transactions are hard. Learn why cross-service atomicity is expensive, when to use it, and when eventual consistency is the right alternative. |
| 14 | Two-Phase Commit: Coordinating a Distributed Decision ← you are here | 2PC ensures distributed atomicity through prepare and commit phases. Learn how it works, the coordinator failure problem, and why it's rarely used in modern systems. |
| 15 | Three-Phase Commit: Solving 2PC's Blocking Problem | 3PC adds a pre-commit phase to eliminate 2PC's blocking problem. Learn how it works, what assumptions it requires, and why it's rarely used in production. |
| 16 | Delivery Semantics: What Does "Delivered" Actually Mean? | Message delivery guarantees define system reliability. Learn what at-most-once, at-least-once, and exactly-once mean, what they cost, and when each is appropriate. |
| 17 | Change Data Capture: Streaming Your Database in Real Time | CDC streams database changes in real time by reading the write-ahead log. Learn how Debezium works, what CDC enables, and when to use it. |
| 18 | Erasure Coding: Fault Tolerance Without Full Replication | Erasure coding stores data across nodes using math, not full replication. Learn how Reed-Solomon works, how S3 uses it, and when it beats 3x replication. |
| 19 | Merkle Trees: Efficiently Finding What's Different | Merkle trees efficiently detect which parts of a large dataset differ between nodes. Learn how Bitcoin, Cassandra, and Git use them for verification and anti-entropy. |
| 20 | Observability: Understanding Your System at Runtime | Logs, metrics, and distributed traces are how you understand a system at runtime. Learn what each pillar provides, the tools involved, and how they work together. |
| 21 | Distributed Systems: Wrap-Up | A recap of all 20 distributed systems concepts and the complete URL shortener architecture spanning all 8 pillars. The final post in the series. |
Two-Phase Commit: Coordinating a Distributed Decision
The problem
Three database nodes must atomically commit a transaction: either all three commit or all three abort. The coordinator must make this decision and ensure all participants do the same, even if some messages are delayed and any node can fail at any moment.
Sending "commit" to all three simultaneously doesn't work — if the message reaches two nodes but is lost to the third (network failure), two commit and one doesn't. The transaction is inconsistent.
You need a protocol that guarantees: if even one participant cannot commit (for any reason), none commit.
The core idea
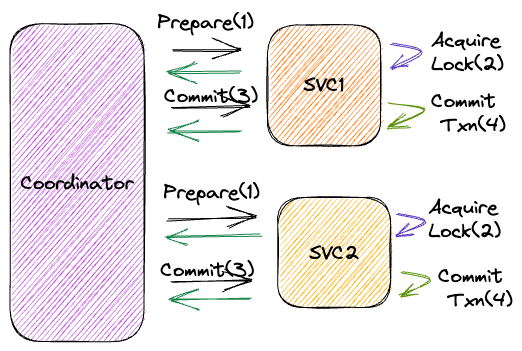
Two-Phase Commit (2PC) coordinates a distributed transaction in two phases: prepare (each participant votes yes or no), then commit or abort (the coordinator sends the unanimous decision). Only after receiving a "yes" from every participant does the coordinator send "commit." Any "no" triggers an "abort" to all.
The analogy: a wedding ceremony with a final question
A wedding officiant (coordinator) asks each party: "Do you take this person to be your lawfully wedded spouse?" Each must say "yes" before the officiant declares them married.
Phase 1: The officiant asks each party privately whether they're sure. Each commits (in their heart) to saying yes, but says nothing final yet — they're in a "prepared" state.
Phase 2: If both said yes, the officiant declares them married (commit). If either hesitates or says no, the ceremony is called off (abort).
If the officiant collapses mid-ceremony after both parties have said "yes" but before the declaration — both parties are stuck in "prepared" state, unsure whether the marriage is legal. This is the 2PC blocking problem.
How 2PC works
Phase 1: Prepare
Coordinator → Prepare → Participant A
Coordinator → Prepare → Participant B
Coordinator → Prepare → Participant C
Each participant:
- Evaluates whether it can commit (checks constraints, acquires row locks)
- Writes a "prepared" record to its WAL (durable — will survive crash)
- Sends Vote-Yes or Vote-No to coordinator
If Vote-Yes: participant is committed to committing if coordinator says so
It will not abort unilaterally
If Vote-No: participant cannot commit (constraint violation, lock conflict)
Phase 2: Commit or Abort
If all votes are Yes:
Coordinator writes "commit" to its log (durable)
Coordinator → Commit → all participants
Each participant commits and releases locks
If any vote is No:
Coordinator → Abort → all participants
Each participant rolls back and releases locks
Why it's safe
Once a participant votes Yes, it is obligated to commit if the coordinator says commit — it cannot independently decide to abort. This obligation is what makes atomicity possible: the coordinator makes exactly one decision, and all prepared participants follow it.
The blocking problem
2PC has one critical flaw: it blocks if the coordinator fails after participants vote Yes but before the commit message is sent.
Participants A, B, C all vote Yes
Coordinator writes "commit" to log
Coordinator CRASHES before sending commit to anyone
Status:
A, B, C: each holds locks, waiting for coordinator
None knows whether to commit or abort
They cannot make a safe independent decision:
- Committing unilaterally might contradict a decision the coordinator
will make to abort when it recovers
- Aborting unilaterally might contradict a commit decision
They must wait for coordinator to recover.
Locks held. Blocking.
In practice, the coordinator typically recovers in seconds to minutes. But during that window, all locked rows are unavailable. For a busy OLTP database, this is a serious availability problem.
Mitigation: the coordinator writes its decision to durable storage before sending messages. On recovery, it can resume from its log and send the correct message to all participants. This reduces the blocking window to the coordinator's recovery time — but doesn't eliminate blocking entirely.
Coordinator failure edge cases
Coordinator fails before writing prepare: coordinator can abort the transaction on recovery — nothing was committed.
Coordinator fails after prepare but before commit: participants are stuck in "prepared" state holding locks until coordinator recovers. This is the blocking case.
Coordinator fails after sending some commits: some participants committed. On recovery, coordinator resends commit to the participants that hadn't acknowledged. All eventually commit — consistency is restored.
Where 2PC is used
XA transactions (PostgreSQL, MySQL, Oracle): the database's native support for distributed transactions. Used in some enterprise systems where cross-database atomicity is required.
JTA (Java Transaction API): enterprise Java applications managing transactions across databases and message brokers.
CockroachDB / Spanner internals: these use a variant of 2PC, but with Raft providing the coordinator's durability guarantee, eliminating the blocking problem.
Avoided in microservices: the lock contention, blocking on coordinator failure, and latency make 2PC unsuitable for most microservices designs. The Saga pattern (Pillar 7, post 09) is almost always preferred.
The one thing to remember
2PC guarantees atomicity across distributed participants through a prepare-then-commit protocol: all must vote yes before any commit. The fundamental weakness is blocking: if the coordinator crashes after participants vote yes but before the commit message is sent, all participants hold locks and wait. This blocking behaviour — not correctness — is what makes 2PC impractical for most microservices designs, and why Saga patterns and distributed databases with native consensus (CockroachDB, Spanner) are preferred.
← Previous: Distributed Transactions — ensuring atomicity across multiple nodes or services when a single ACID transaction isn't possible.
→ Next: Three-Phase Commit — the protocol designed to eliminate 2PC's blocking problem, and why it's rarely used in practice despite solving it.




