Split-Brain: When Two Nodes Both Think They're the Leader
Series: System Design · Distributed Systems — Pillar 8 of 8
Systems Design
| # | Post | What it covers |
|---|---|---|
| 00 | Distributed Systems: What Happens When Machines Disagree | Twenty concepts covering network partitions, consensus, clocks, distributed transactions, CDC, erasure coding, and observability. The final pillar. |
| 01 | Network Partitions: The Failure Mode You Can't Design Away | Network partitions are inevitable. Learn what happens when nodes can't communicate, how systems choose between availability and consistency, and what that means in practice. |
| 02 | Split-Brain: When Two Nodes Both Think They're the Leader ← you are here | Split-brain occurs when two nodes both believe they're the primary. Learn how it happens, why it causes data corruption, and how STONITH and fencing prevent it. |
| 03 | Heartbeats: How Nodes Know Their Peers Are Alive | Heartbeats let nodes detect peer failures. Learn how timeouts, phi accrual failure detectors, and the tradeoff between false positives and detection speed work. |
| 04 | Leader Election: Agreeing on Who's in Charge | Leader election coordinates which node acts as primary. Learn the bully algorithm, Raft-based election, and why exactly-one-leader guarantees are hard to achieve. |
| 05 | Consensus Algorithms: Agreeing on a Value Across Failures | Consensus lets distributed nodes agree on a value despite failures. Learn what FLP impossibility means, what Paxos and Raft provide, and where consensus is used. |
| 06 | Quorum: How Many Nodes Must Agree? | Quorum determines how many nodes must agree for an operation to succeed. Learn how R + W > N ensures consistency in distributed databases like Cassandra and DynamoDB. |
| 07 | Paxos: The Algorithm That Started It All | Paxos is the foundational distributed consensus algorithm. Learn how its two phases work, why it's hard to implement, and what systems use it in production. |
| 08 | Raft: Consensus Made Understandable | Raft makes distributed consensus understandable. Learn how leader election, log replication, and safety work in the algorithm that powers etcd, CockroachDB, and TiKV. |
| 09 | Gossip Protocol: Decentralised Cluster Communication | Gossip protocols propagate information across a cluster without a central coordinator. Learn how epidemic spreading works and where it's used in production. |
| 10 | Logical Clocks: When Physical Time Isn't Enough | Physical clocks drift and can't establish event order in distributed systems. Logical clocks track causality instead. Learn why this matters and how it works. |
| 11 | Lamport Timestamps: Ordering Events Without a Global Clock | Lamport timestamps assign logical counters to events to establish causal order in distributed systems. Learn how they work and what they can and can't tell you. |
| 12 | Vector Clocks: Knowing When Events Are Truly Concurrent | Vector clocks detect causality and concurrency in distributed systems. Learn how they work, how Dynamo uses them for conflict detection, and their limitations. |
| 13 | Distributed Transactions: When One Machine Isn't Enough | Distributed transactions are hard. Learn why cross-service atomicity is expensive, when to use it, and when eventual consistency is the right alternative. |
| 14 | Two-Phase Commit: Coordinating a Distributed Decision | 2PC ensures distributed atomicity through prepare and commit phases. Learn how it works, the coordinator failure problem, and why it's rarely used in modern systems. |
| 15 | Three-Phase Commit: Solving 2PC's Blocking Problem | 3PC adds a pre-commit phase to eliminate 2PC's blocking problem. Learn how it works, what assumptions it requires, and why it's rarely used in production. |
| 16 | Delivery Semantics: What Does "Delivered" Actually Mean? | Message delivery guarantees define system reliability. Learn what at-most-once, at-least-once, and exactly-once mean, what they cost, and when each is appropriate. |
| 17 | Change Data Capture: Streaming Your Database in Real Time | CDC streams database changes in real time by reading the write-ahead log. Learn how Debezium works, what CDC enables, and when to use it. |
| 18 | Erasure Coding: Fault Tolerance Without Full Replication | Erasure coding stores data across nodes using math, not full replication. Learn how Reed-Solomon works, how S3 uses it, and when it beats 3x replication. |
| 19 | Merkle Trees: Efficiently Finding What's Different | Merkle trees efficiently detect which parts of a large dataset differ between nodes. Learn how Bitcoin, Cassandra, and Git use them for verification and anti-entropy. |
| 20 | Observability: Understanding Your System at Runtime | Logs, metrics, and distributed traces are how you understand a system at runtime. Learn what each pillar provides, the tools involved, and how they work together. |
| 21 | Distributed Systems: Wrap-Up | A recap of all 20 distributed systems concepts and the complete URL shortener architecture spanning all 8 pillars. The final post in the series. |
Split-Brain: When Two Nodes Both Think They're the Leader
The problem
Your PostgreSQL cluster has a primary and two replicas managed by Patroni. At 3am, the primary becomes unresponsive — it's not crashing, but it's heavily loaded and responding to heartbeats very slowly. Patroni's timeout fires. The HA agent, seeing no heartbeat responses, declares the primary dead and promotes a replica.
But the primary wasn't dead. It was slow. When it recovers three seconds later, it has no idea a new primary was promoted. It starts accepting writes again. So does the newly promoted primary.
For sixty seconds, two nodes are both accepting writes to the same PostgreSQL cluster. Users are creating links on one primary; other users are creating links on the other. When the confusion is discovered and resolved — one primary wins — sixty seconds of writes on the losing primary are gone. Or worse: the two primaries diverged in conflicting ways that require manual reconciliation.
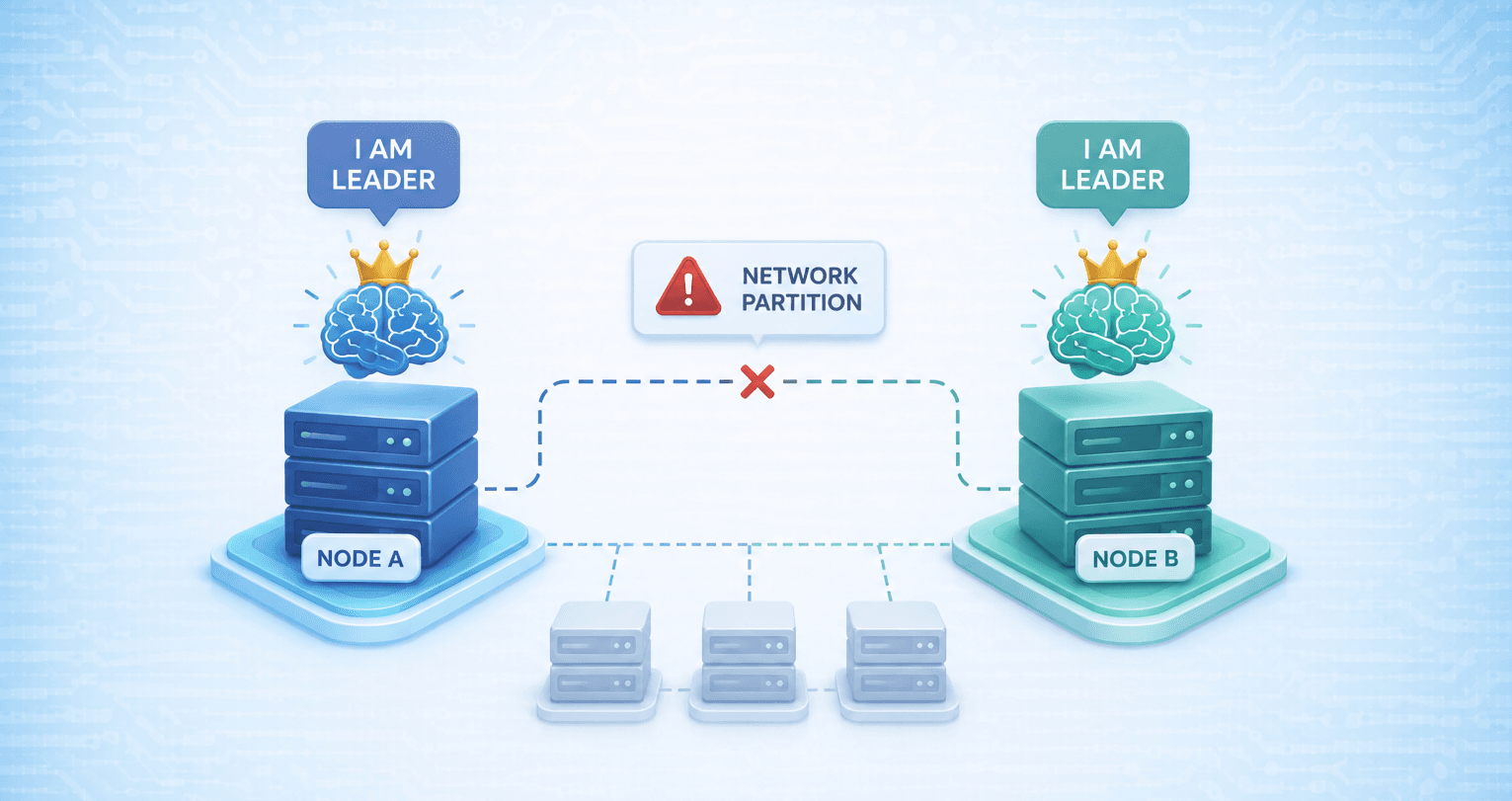
This is split-brain: a partition (or timeout) causes multiple nodes to simultaneously act as the authoritative primary.
The core idea
Split-brain is the state where a distributed system has two (or more) nodes simultaneously acting as the primary or leader, each accepting writes independently. It's caused by partition or timeout misdetection, and it's dangerous: the two primaries diverge, and reconciling their state is expensive or impossible without data loss.
The analogy: two branch managers running the same bank account
A customer's bank account is managed from headquarters. Due to a communication outage, two branch managers each believe they are the authoritative custodian of the account. Both accept deposits and withdrawals. When communication is restored, the account has different balances in each record. Resolving which transactions are "real" may require manual investigation of every transaction since the outage.
Split-brain is the database equivalent. Both leaders accepted real writes from real clients. Choosing a winner discards the other's writes.
How split-brain happens
The grey failure
The most dangerous split-brain scenario involves a "grey failure" — the primary isn't crashed, it's degraded. Network packets arrive but slowly. Heartbeats are delayed past the timeout threshold. The HA agent declares the primary dead.
But the primary is still running. Its network issues resolve. It doesn't know it was deposed. Both it and the newly promoted replica accept writes.
Two-node clusters: inherently dangerous
A two-node cluster (one primary, one replica) is the worst configuration for split-brain. If the primary appears to fail:
- The replica sees no heartbeat → promotes itself
- If the primary was actually alive, both are now primary
- No quorum is possible with two nodes — you can't prove the old primary is truly dead
Three-node clusters (or larger odd numbers) can use quorum: if a node can't reach a majority, it must step down. A minority of one cannot unilaterally declare itself leader.
Prevention: STONITH and fencing
The solution to split-brain is not detecting it — it's preventing the deposed primary from doing harm. The technique is fencing: ensuring the old primary cannot write to the database after it's been replaced.
STONITH: Shoot The Other Node In The Head
STONITH is the deliberate termination or isolation of the old primary when a new one is promoted:
Power fencing: cut the power to the old primary's server via a remote power switch (IPMI, iLO, DRAC). If the machine is off, it can't write.
Network fencing: block the old primary's IP from reaching the database storage via firewall rules. The machine runs but can't write.
Storage fencing (SCSI reservations, disk locks): reserve the shared storage exclusively for the new primary. The old primary's write operations fail at the storage level.
Cloud instance termination: on AWS/GCP/Azure, terminate the old primary's instance via API as part of the failover procedure.
Patroni's approach
Patroni integrates fencing into its failover procedure. Before promoting a replica, Patroni:
- Attempts to contact the primary and demote it gracefully (send a demotion signal)
- If that fails, executes the configured fencing action (e.g., terminate the EC2 instance)
- Only promotes the replica after confirming the old primary is fenced
If the fencing action fails, Patroni does not proceed with promotion — it's safer to have no primary at all than two. This is the "availability vs safety" tradeoff: the cluster remains unavailable (no writes) rather than risk data corruption from two primaries.
Quorum-based prevention
Raft and Paxos (covered in posts 07 and 08) solve split-brain structurally: a leader can only be elected if it receives votes from a majority of nodes. A partitioned minority cannot elect a leader — it doesn't have enough votes. So only one leader can exist at a time: the one with majority support.
Detection after the fact
Despite prevention, split-brain can still occur with improperly configured systems. Detection:
Sequence number divergence: the primary's WAL sequence number and the replica's sequence number are compared after failover. If the replica was promoted while the old primary was still writing, their WAL will have diverged — the replica will have different entries at the same position. This is visible immediately on reconnection.
Write conflict detection: if both primaries wrote to the same row with different values, the conflict is visible in the data.
Replication monitoring: monitoring tools track the health of the replication topology continuously. Two simultaneous primaries trigger an alert.
The one thing to remember
Split-brain is not just a data inconsistency — it's a silent data loss event. When the dust settles, one primary wins and the other's writes are discarded. The solution is not better detection but better prevention: ensure the old primary is definitively fenced before the new one is promoted, and use quorum-based systems that structurally prevent two leaders from existing simultaneously. Never run critical databases in a two-node configuration without a tiebreaker.
← Previous: Network Partitions — what happens when nodes can't communicate
→ Next: Heartbeats — the mechanism by which nodes detect that their peers have failed, and why timeout calibration is harder than it looks.




