Leader Election: Agreeing on Who's in Charge
Series: System Design · Distributed Systems — Pillar 8 of 8
Systems Design
| # | Post | What it covers |
|---|---|---|
| 00 | Distributed Systems: What Happens When Machines Disagree | Twenty concepts covering network partitions, consensus, clocks, distributed transactions, CDC, erasure coding, and observability. The final pillar. |
| 01 | Network Partitions: The Failure Mode You Can't Design Away | Network partitions are inevitable. Learn what happens when nodes can't communicate, how systems choose between availability and consistency, and what that means in practice. |
| 02 | Split-Brain: When Two Nodes Both Think They're the Leader | Split-brain occurs when two nodes both believe they're the primary. Learn how it happens, why it causes data corruption, and how STONITH and fencing prevent it. |
| 03 | Heartbeats: How Nodes Know Their Peers Are Alive | Heartbeats let nodes detect peer failures. Learn how timeouts, phi accrual failure detectors, and the tradeoff between false positives and detection speed work. |
| 04 | Leader Election: Agreeing on Who's in Charge ← you are here | Leader election coordinates which node acts as primary. Learn the bully algorithm, Raft-based election, and why exactly-one-leader guarantees are hard to achieve. |
| 05 | Consensus Algorithms: Agreeing on a Value Across Failures | Consensus lets distributed nodes agree on a value despite failures. Learn what FLP impossibility means, what Paxos and Raft provide, and where consensus is used. |
| 06 | Quorum: How Many Nodes Must Agree? | Quorum determines how many nodes must agree for an operation to succeed. Learn how R + W > N ensures consistency in distributed databases like Cassandra and DynamoDB. |
| 07 | Paxos: The Algorithm That Started It All | Paxos is the foundational distributed consensus algorithm. Learn how its two phases work, why it's hard to implement, and what systems use it in production. |
| 08 | Raft: Consensus Made Understandable | Raft makes distributed consensus understandable. Learn how leader election, log replication, and safety work in the algorithm that powers etcd, CockroachDB, and TiKV. |
| 09 | Gossip Protocol: Decentralised Cluster Communication | Gossip protocols propagate information across a cluster without a central coordinator. Learn how epidemic spreading works and where it's used in production. |
| 10 | Logical Clocks: When Physical Time Isn't Enough | Physical clocks drift and can't establish event order in distributed systems. Logical clocks track causality instead. Learn why this matters and how it works. |
| 11 | Lamport Timestamps: Ordering Events Without a Global Clock | Lamport timestamps assign logical counters to events to establish causal order in distributed systems. Learn how they work and what they can and can't tell you. |
| 12 | Vector Clocks: Knowing When Events Are Truly Concurrent | Vector clocks detect causality and concurrency in distributed systems. Learn how they work, how Dynamo uses them for conflict detection, and their limitations. |
| 13 | Distributed Transactions: When One Machine Isn't Enough | Distributed transactions are hard. Learn why cross-service atomicity is expensive, when to use it, and when eventual consistency is the right alternative. |
| 14 | Two-Phase Commit: Coordinating a Distributed Decision | 2PC ensures distributed atomicity through prepare and commit phases. Learn how it works, the coordinator failure problem, and why it's rarely used in modern systems. |
| 15 | Three-Phase Commit: Solving 2PC's Blocking Problem | 3PC adds a pre-commit phase to eliminate 2PC's blocking problem. Learn how it works, what assumptions it requires, and why it's rarely used in production. |
| 16 | Delivery Semantics: What Does "Delivered" Actually Mean? | Message delivery guarantees define system reliability. Learn what at-most-once, at-least-once, and exactly-once mean, what they cost, and when each is appropriate. |
| 17 | Change Data Capture: Streaming Your Database in Real Time | CDC streams database changes in real time by reading the write-ahead log. Learn how Debezium works, what CDC enables, and when to use it. |
| 18 | Erasure Coding: Fault Tolerance Without Full Replication | Erasure coding stores data across nodes using math, not full replication. Learn how Reed-Solomon works, how S3 uses it, and when it beats 3x replication. |
| 19 | Merkle Trees: Efficiently Finding What's Different | Merkle trees efficiently detect which parts of a large dataset differ between nodes. Learn how Bitcoin, Cassandra, and Git use them for verification and anti-entropy. |
| 20 | Observability: Understanding Your System at Runtime | Logs, metrics, and distributed traces are how you understand a system at runtime. Learn what each pillar provides, the tools involved, and how they work together. |
| 21 | Distributed Systems: Wrap-Up | A recap of all 20 distributed systems concepts and the complete URL shortener architecture spanning all 8 pillars. The final post in the series. |
Leader Election: Agreeing on Who's in Charge
The problem
Your Cassandra cluster has six nodes. One serves as the coordinator for a given operation. Your Kafka cluster has multiple brokers; one acts as the controller. Your PostgreSQL HA setup has a primary; the Patroni agent monitors and manages it.
When the current leader fails, something must happen automatically and correctly: a new leader must be elected, the cluster must agree on exactly one leader, and that leader must be the most qualified candidate (typically the node with the most up-to-date data). This must happen quickly (to minimise downtime) and safely (to avoid split-brain).
Leader election is the mechanism that makes this work.
The core idea
Leader election is the process by which a group of distributed nodes agrees on exactly one node to act as the coordinator, primary, or leader. The elected leader has special authority — it accepts writes, coordinates decisions, or acts as the authoritative source of truth. The key properties required: safety (at most one leader at any time) and liveness (a leader is eventually elected when the current one fails).
The analogy: a parliamentary vote after a vacant prime ministerial seat
The prime minister resigns. Parliament must elect a new one. Rules ensure: only one candidate can win (safety), the process must complete in finite time (liveness), and the winner must have majority support (quorum).
If the vote is split 50/50, no winner is declared and parliament tries again. A candidate who wins a majority is appointed and takes office immediately.
Distributed leader election uses the same structure: candidates campaign for votes, quorum determines the winner, and only one candidate can achieve majority.
How leader election works
Requirements
Safety: at most one leader exists at any given time. Two simultaneous leaders cause split-brain.
Liveness: if the current leader fails, a new leader is eventually elected. The system doesn't hang indefinitely.
Stability: a new leader is not elected unnecessarily. Frequent elections are disruptive — each election causes a brief unavailability window.
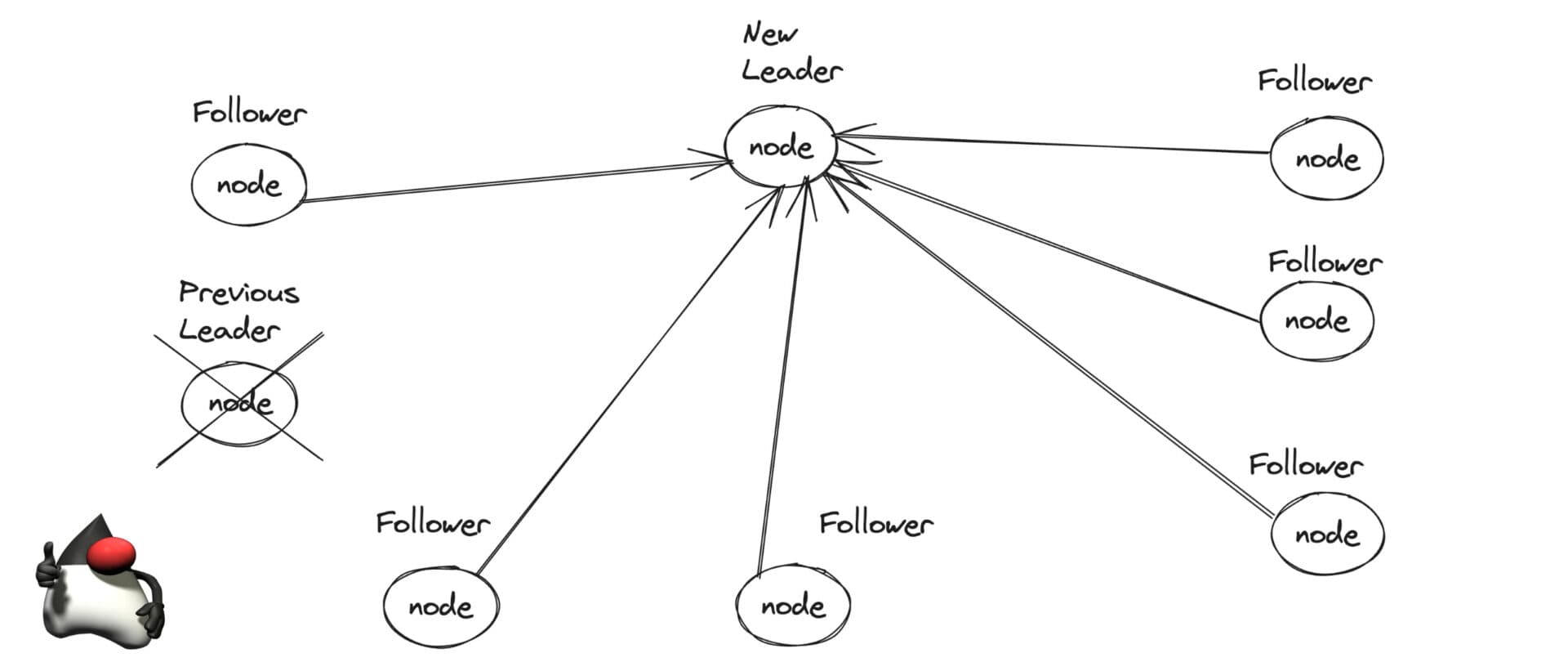
The Bully Algorithm
The simplest algorithm: when a node detects that the leader has failed, it sends an election message to all nodes with higher IDs. If no higher-ID node responds, the node declares itself leader. If a higher-ID node responds, it takes over the election.
Nodes: A(1), B(2), C(3), D(4), E(5)
D(4) fails.
C(3) notices → sends election to D(4), E(5)
E(5) responds: "I'm higher, I'll take over"
E(5) sends election to no one (highest)
E(5) declares itself leader, broadcasts victory to all
Weaknesses: the node with the highest ID always wins, even if it's not the most up-to-date. Also, a briefly-unavailable high-ID node triggers a cascade of unnecessary elections. Fine for educational purposes, rarely used in production.
Raft-based election (the production standard)
Raft (covered in depth in post 08) uses a term-based election:
- Each node starts as a follower, waiting for heartbeats from the leader
- If a follower doesn't receive a heartbeat within
electionTimeout, it becomes a candidate and increments its term (a monotonically increasing counter) - The candidate votes for itself and sends
RequestVoteRPCs to all other nodes - A node grants its vote if: it hasn't voted in this term yet, AND the candidate's log is at least as up-to-date as its own
- The candidate wins if it receives votes from a majority of nodes
- The winner broadcasts its leadership and begins sending heartbeats
Term numbers prevent split-brain: a node that receives a message with a higher term immediately updates its term and reverts to follower. An old leader that recovers from a partition finds it has a stale term — it immediately steps down.
Log up-to-date check: a candidate can only win if its log is at least as current as any voter's. This ensures the elected leader has all committed entries — critical for maintaining the replicated log's consistency.
ZooKeeper-based election
ZooKeeper provides a distributed coordination service used for leader election by many systems (Kafka, HBase, older Hadoop).
The ZooKeeper recipe: candidates create ephemeral sequential znodes under a path like /election/candidate_. The node with the lowest sequence number is the leader. Each non-leader watches the znode immediately preceding it; if that znode is deleted (its holder crashed), the watcher takes over as the new leader.
/election/candidate_0000000001 (leader — watching nothing)
/election/candidate_0000000002 (watching 0001)
/election/candidate_0000000003 (watching 0002)
0001 crashes → ZK deletes its ephemeral znode
0002 receives watch notification → checks: am I now the lowest? Yes → becomes leader
ZooKeeper's strong consistency guarantees ensure exactly one node sees the lowest sequence number at any time.
The election gap
During an election, there is no leader. Write operations that require a leader are unavailable. This window — from when the old leader fails until a new one is established — is the election gap.
In Raft with typical timeouts:
- Election timeout: 150–300ms
- If the first candidate wins immediately: ~150ms gap
- If elections split (two candidates start simultaneously, no majority): timeout and retry; can extend to 1–2 seconds
For PostgreSQL HA (Patroni): the election gap includes heartbeat detection time + fencing time + promotion time: typically 30–60 seconds.
This is why the choice of timeout matters so much: a shorter election timeout means faster recovery but more false-positive elections; a longer timeout means fewer disruptions but longer recovery from real failures.
Tradeoffs
Election speed vs stability. Fast elections (short timeouts) minimise downtime from real failures but trigger frequently on transient network hiccups. Slow elections minimise disruption but extend the unavailability window on genuine failures.
Quorum requirement vs availability. Requiring a majority vote (⌊N/2⌋ + 1) means a cluster of 5 tolerates 2 failures. A cluster of 3 tolerates 1 failure but loses availability if a second node fails before the first is replaced. This is the fundamental tension between fault tolerance and availability.
Leader bottleneck. Having one leader means all decisions flow through one node. This is fine for coordination tasks (log replication, configuration management). For high-throughput data systems (Cassandra), leaderless designs distribute writes across all nodes and use quorum for consistency instead.
The one thing to remember
Leader election must guarantee at most one leader at any time (safety) while ensuring a leader is always eventually available (liveness). Raft achieves both through term-based voting: a candidate must win a majority, terms prevent old leaders from reclaiming authority after recovery, and the log up-to-date check ensures the winner has all committed data. The election gap — the window of unavailability between a leader failure and its successor's election — is the fundamental cost of leader-based coordination.
← Previous: Heartbeats — the mechanism by which nodes detect that their peers have failed, and why timeout calibration is harder than it looks.
→ Next: Consensus Algorithms — the broader category of algorithms (Paxos, Raft, Zab) that allow distributed nodes to agree on a value despite failures.




