Heartbeats: How Nodes Know Their Peers Are Alive
Series: System Design · Distributed Systems — Pillar 8 of 8
Systems Design
| # | Post | What it covers |
|---|---|---|
| 00 | Distributed Systems: What Happens When Machines Disagree | Twenty concepts covering network partitions, consensus, clocks, distributed transactions, CDC, erasure coding, and observability. The final pillar. |
| 01 | Network Partitions: The Failure Mode You Can't Design Away | Network partitions are inevitable. Learn what happens when nodes can't communicate, how systems choose between availability and consistency, and what that means in practice. |
| 02 | Split-Brain: When Two Nodes Both Think They're the Leader | Split-brain occurs when two nodes both believe they're the primary. Learn how it happens, why it causes data corruption, and how STONITH and fencing prevent it. |
| 03 | Heartbeats: How Nodes Know Their Peers Are Alive ← you are here | Heartbeats let nodes detect peer failures. Learn how timeouts, phi accrual failure detectors, and the tradeoff between false positives and detection speed work. |
| 04 | Leader Election: Agreeing on Who's in Charge | Leader election coordinates which node acts as primary. Learn the bully algorithm, Raft-based election, and why exactly-one-leader guarantees are hard to achieve. |
| 05 | Consensus Algorithms: Agreeing on a Value Across Failures | Consensus lets distributed nodes agree on a value despite failures. Learn what FLP impossibility means, what Paxos and Raft provide, and where consensus is used. |
| 06 | Quorum: How Many Nodes Must Agree? | Quorum determines how many nodes must agree for an operation to succeed. Learn how R + W > N ensures consistency in distributed databases like Cassandra and DynamoDB. |
| 07 | Paxos: The Algorithm That Started It All | Paxos is the foundational distributed consensus algorithm. Learn how its two phases work, why it's hard to implement, and what systems use it in production. |
| 08 | Raft: Consensus Made Understandable | Raft makes distributed consensus understandable. Learn how leader election, log replication, and safety work in the algorithm that powers etcd, CockroachDB, and TiKV. |
| 09 | Gossip Protocol: Decentralised Cluster Communication | Gossip protocols propagate information across a cluster without a central coordinator. Learn how epidemic spreading works and where it's used in production. |
| 10 | Logical Clocks: When Physical Time Isn't Enough | Physical clocks drift and can't establish event order in distributed systems. Logical clocks track causality instead. Learn why this matters and how it works. |
| 11 | Lamport Timestamps: Ordering Events Without a Global Clock | Lamport timestamps assign logical counters to events to establish causal order in distributed systems. Learn how they work and what they can and can't tell you. |
| 12 | Vector Clocks: Knowing When Events Are Truly Concurrent | Vector clocks detect causality and concurrency in distributed systems. Learn how they work, how Dynamo uses them for conflict detection, and their limitations. |
| 13 | Distributed Transactions: When One Machine Isn't Enough | Distributed transactions are hard. Learn why cross-service atomicity is expensive, when to use it, and when eventual consistency is the right alternative. |
| 14 | Two-Phase Commit: Coordinating a Distributed Decision | 2PC ensures distributed atomicity through prepare and commit phases. Learn how it works, the coordinator failure problem, and why it's rarely used in modern systems. |
| 15 | Three-Phase Commit: Solving 2PC's Blocking Problem | 3PC adds a pre-commit phase to eliminate 2PC's blocking problem. Learn how it works, what assumptions it requires, and why it's rarely used in production. |
| 16 | Delivery Semantics: What Does "Delivered" Actually Mean? | Message delivery guarantees define system reliability. Learn what at-most-once, at-least-once, and exactly-once mean, what they cost, and when each is appropriate. |
| 17 | Change Data Capture: Streaming Your Database in Real Time | CDC streams database changes in real time by reading the write-ahead log. Learn how Debezium works, what CDC enables, and when to use it. |
| 18 | Erasure Coding: Fault Tolerance Without Full Replication | Erasure coding stores data across nodes using math, not full replication. Learn how Reed-Solomon works, how S3 uses it, and when it beats 3x replication. |
| 19 | Merkle Trees: Efficiently Finding What's Different | Merkle trees efficiently detect which parts of a large dataset differ between nodes. Learn how Bitcoin, Cassandra, and Git use them for verification and anti-entropy. |
| 20 | Observability: Understanding Your System at Runtime | Logs, metrics, and distributed traces are how you understand a system at runtime. Learn what each pillar provides, the tools involved, and how they work together. |
| 21 | Distributed Systems: Wrap-Up | A recap of all 20 distributed systems concepts and the complete URL shortener architecture spanning all 8 pillars. The final post in the series. |
Heartbeats: How Nodes Know Their Peers Are Alive
The problem
Node A has been healthy for months. At 2:47am, it crashes silently — no graceful shutdown, no final message to its peers. It's just gone.
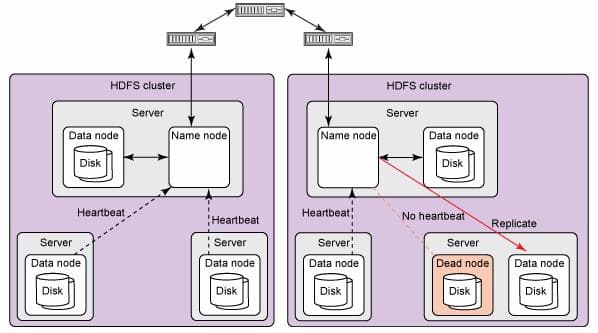
How does the rest of the cluster know? There was no goodbye. Node A doesn't announce its failure — a crashed process can't send notifications. The other nodes must infer the failure from the absence of communication.
But absence of communication is ambiguous. Maybe Node A crashed. Maybe it's very busy and just slow to respond. Maybe the network between the observer and Node A failed, but Node A itself is fine and still accepting writes from other nodes (the split-brain precursor).
The mechanism clusters use to detect failures is the heartbeat: periodic signals that prove liveness, with absence treated as evidence of failure after a calibrated timeout.
The core idea
A heartbeat is a periodic message sent by a node to prove it's alive. Peers that don't receive heartbeats within a timeout period treat the sender as failed. The timeout must be tuned: too short causes false positives (healthy-but-slow nodes declared dead), too long causes slow failure detection (dead nodes remain in rotation for too long).
The analogy: a check-in call
A field researcher in a remote area checks in with headquarters every four hours. If headquarters doesn't receive a check-in by the expected time, they consider the researcher to be in trouble and initiate a search.
The check-in is the heartbeat. The four-hour window is the timeout. A missed check-in might mean the researcher is in danger — or might mean their radio battery died, or they're in a canyon with no signal. The decision to act (search) vs wait is the failure detection tradeoff: act too soon and waste resources; act too late and the researcher suffers longer.
How heartbeats work
The basic mechanism
Every T seconds:
Node A → sends heartbeat to all peers (or to a central monitor)
Peers → record "last heard from A at time t"
Continuously:
Peer checks: (current_time - last_heard_from_A) > timeout?
No: A is alive
Yes: A is suspected dead → trigger failure response
In Zookeeper: clients maintain a session with the ZooKeeper ensemble. The client sends heartbeats every tickTime milliseconds. If the session expires (no heartbeat received within sessionTimeout), ZooKeeper revokes the session's ephemeral nodes — triggering watches that notify other clients of the failure.
In Raft: the leader sends periodic heartbeat AppendEntries RPCs to followers. If a follower doesn't receive a heartbeat within electionTimeout, it assumes the leader has failed and starts a new election.
In Kubernetes: the kubelet on each node sends heartbeats to the API server every 10 seconds. If the API server doesn't hear from a node for 40 seconds (4 missed heartbeats), it marks the node as NotReady. After 5 minutes of NotReady, pods are evicted.
Timeout calibration: the core tradeoff
Too short a timeout → false positives: a node that's busy or experiencing a brief network hiccup is declared dead. The cluster initiates a costly failover. The "dead" node recovers and finds a new primary already elected — split-brain risk.
Too long a timeout → slow detection: a genuinely dead node remains in rotation for too long. Requests are routed to it and time out from the client's perspective. Recovery is delayed.
The right timeout depends on:
- Expected network jitter (p99 round-trip time in the cluster)
- The cost of a false positive (unnecessary failover is expensive)
- The cost of slow detection (failed nodes in rotation cause user-visible errors)
A common starting point: timeout = p99_RTT × 10. If the p99 round-trip time in the cluster is 5ms, a 50ms timeout fires quickly. If network jitter is higher (cross-region), 1–5 second timeouts are typical.
Phi Accrual Failure Detector
Rather than a binary "alive/dead" decision at a fixed threshold, the phi accrual failure detector (used by Cassandra and Akka) computes a continuous suspicion level φ based on the history of heartbeat intervals.
If heartbeats typically arrive every 200ms with a standard deviation of 10ms, a heartbeat that's 500ms late is more suspicious than one that's 250ms late — the detector captures this. As φ grows, the consuming system can choose to act (declare failure) when φ exceeds a configured threshold rather than at a fixed absolute timeout.
φ = 0: definitely alive
φ = 1: somewhat suspicious
φ = 5: likely failed (act)
φ = 10: almost certainly failed
The advantage: the failure detector adapts to observed network behaviour. During high load (when heartbeats legitimately arrive later), φ rises more slowly than during normal conditions — fewer false positives under load.
What happens on failure detection
Cluster membership update: the failed node is removed from the cluster's membership view. New requests are not routed to it.
Leader election trigger: if the failed node was the leader, an election begins (covered in the next post).
Replica rebalancing: in Cassandra, the failure of a node triggers the ring topology to rebalance. Read and write operations route around the failed node.
Pod eviction (Kubernetes): pods on the failed node are rescheduled to healthy nodes.
Tradeoffs
Heartbeat frequency vs network overhead. Sending heartbeats every 100ms across 100 nodes generates 10,000 messages/second just for liveness checks. High heartbeat frequency improves detection speed but adds cluster overhead. Gossip-based failure detection (post 09) distributes this overhead.
Detection speed vs false positive rate. The key design tension. Production systems often use conservative timeouts (5–30 seconds) to avoid the cost of false-positive failovers, accepting that a few extra seconds of downtime is preferable to the disruption of an unnecessary election.
Network partitions complicate interpretation. A node that's not responding to heartbeats may be: crashed, overloaded, or unreachable due to a partition. A heartbeat failure can't distinguish between these. Fencing (post 02) ensures safety regardless of the cause.
The one thing to remember
Heartbeats are how distributed nodes detect failure in the absence of explicit notifications — a node that stops sending heartbeats is presumed dead after a calibrated timeout. The timeout is the most important configuration parameter: too short causes false positives and unnecessary failovers; too long delays recovery from real failures. The phi accrual failure detector is a more sophisticated alternative that adapts to observed network behaviour, reducing false positives without sacrificing detection speed.
← Previous: Split-Brain — what happens when a partition causes two nodes to simultaneously believe they are the leader.
→ Next: Leader Election — when a leader fails, the cluster must agree on a new one; this post covers how that agreement is reached safely.




