HyperLogLog: Counting Distinct Items Without Storing Them
Series: System Design · Scalability & Infrastructure — Pillar 6 of 8
Systems Design
| # | Post | What it covers |
|---|---|---|
| 00 | Scalability & Infrastructure: The Layer Between Your Code and the Internet | Nine concepts covering load balancing, rate limiting, proxies, compression, and probabilistic data structures that keep large systems fast and reliable. |
| 01 | Client-Server Architecture: The Model Everything Else Builds On | Client-server is the foundational model for distributed systems. Learn what clients and servers know, where state lives, and how the model scales. |
| 02 | Load Balancing: Distributing Traffic Across Servers | Load balancers distribute traffic across servers for scale and availability. Learn how they work, what types exist, and what they require of backend servers. |
| 03 | Load Balancing Algorithms: How Traffic Is Distributed | Round robin, least connections, IP hash, weighted — each algorithm makes different tradeoffs. Learn how to choose the right one for your workload. |
| 04 | Rate Limiting: Protecting Services from Overload | Rate limiting protects services from overload and abuse. Learn how token bucket, leaky bucket, and sliding window algorithms work and when to use each. |
| 05 | Proxy vs Reverse Proxy: Which Way Does It Face? | Forward proxies protect clients; reverse proxies protect servers. Learn how each works, what Nginx and Cloudflare do, and when you need which. |
| 06 | Data Compression: Smaller, Faster, Cheaper | Compression reduces bandwidth and storage costs. Learn how Gzip, Brotli, LZ4, and zstd work, where to apply them, and the CPU tradeoffs involved. |
| 07 | Checksums: Detecting Corruption Before It Becomes a Catastrophe | Checksums detect silent data corruption in transit and storage. Learn how CRC32, MD5, and SHA-256 work and where to apply them in distributed systems. |
| 08 | Bloom Filters: Answering "Have I Seen This?" Without Storing Everything | A Bloom filter answers "have I seen this?" in constant memory. Learn how they work, why false positives are acceptable, and where they're used in production. |
| 09 | HyperLogLog: Counting Distinct Items Without Storing Them ← you are here | HyperLogLog counts distinct values in ~1.5 KB of memory with <2% error. Learn how it works and why Redis, BigQuery, and Postgres use it. |
| 10 | Scalability & Infrastructure: Wrap-Up | A recap of all 9 scalability concepts: load balancing, rate limiting, proxies, compression, checksums, Bloom filters, and HyperLogLog. How they fit together. |
HyperLogLog: Counting Distinct Items Without Storing Them
The problem
Your URL shortener's analytics dashboard shows, per link: total clicks and unique visitors (distinct IP addresses). Total clicks is trivial — a counter incremented on every click. Unique visitors is the hard one.
Unique visitors requires counting distinct values: how many different IP addresses have clicked this link? The naive approach: maintain a set of all IP addresses seen and take its size. At a million unique visitors per link per day, that set holds a million IP strings — roughly 15MB per link. At a million links, that's 15TB of Redis memory for one day's unique visitor data.
An alternative: use a database aggregate. SELECT COUNT(DISTINCT ip_address) FROM clicks WHERE link_id = 'x7Kp2' AND date = '2025-06-01'. On a table with billions of click rows, this query takes tens of seconds. Not acceptable for a dashboard that loads on every page.
You need to count distinct items, at high speed, without storing every item you've seen.
The core idea
HyperLogLog (HLL) is a probabilistic algorithm that estimates the number of distinct elements in a multiset (a stream with repetitions) using constant memory (~1.5 KB in Redis's implementation), with a guaranteed relative error of less than 2%. It trades exact accuracy for constant memory — the estimate is close enough for analytics use cases, and the memory savings are enormous.
The analogy: estimating a crowd by the highest raffle number
Imagine estimating the attendance at a large festival without a gate count. As you walk through the crowd, you ask random people their raffle ticket number. You note the highest number you've seen.
If ticket numbers are assigned randomly from 1 to infinity, and the highest you've seen is 12,847, a reasonable estimate is that roughly 12,847 people attended — because if only a hundred people were there, you'd almost certainly have seen a much lower maximum. If fifty thousand were there, you'd probably have seen a number much higher than 12,847.
This is the intuition behind HyperLogLog. It uses a hash function to map each item to a number. It observes the maximum number of leading zeros in those hash values. More leading zeros implies more distinct items were hashed (because a hash with many leading zeros is rare — seeing one means many items were tried).
The analogy breaks down on precision — the naive maximum-observation approach has high variance. HyperLogLog improves this dramatically using multiple registers and harmonic mean averaging.
How it works
The trailing zeros observation
Hash each item to a binary string:
"203.0.113.42" → hash → 0b00011010... (3 leading zeros)
"198.51.100.7" → hash → 0b01001101... (1 leading zero)
"10.0.0.1" → hash → 0b00001101... (4 leading zeros)
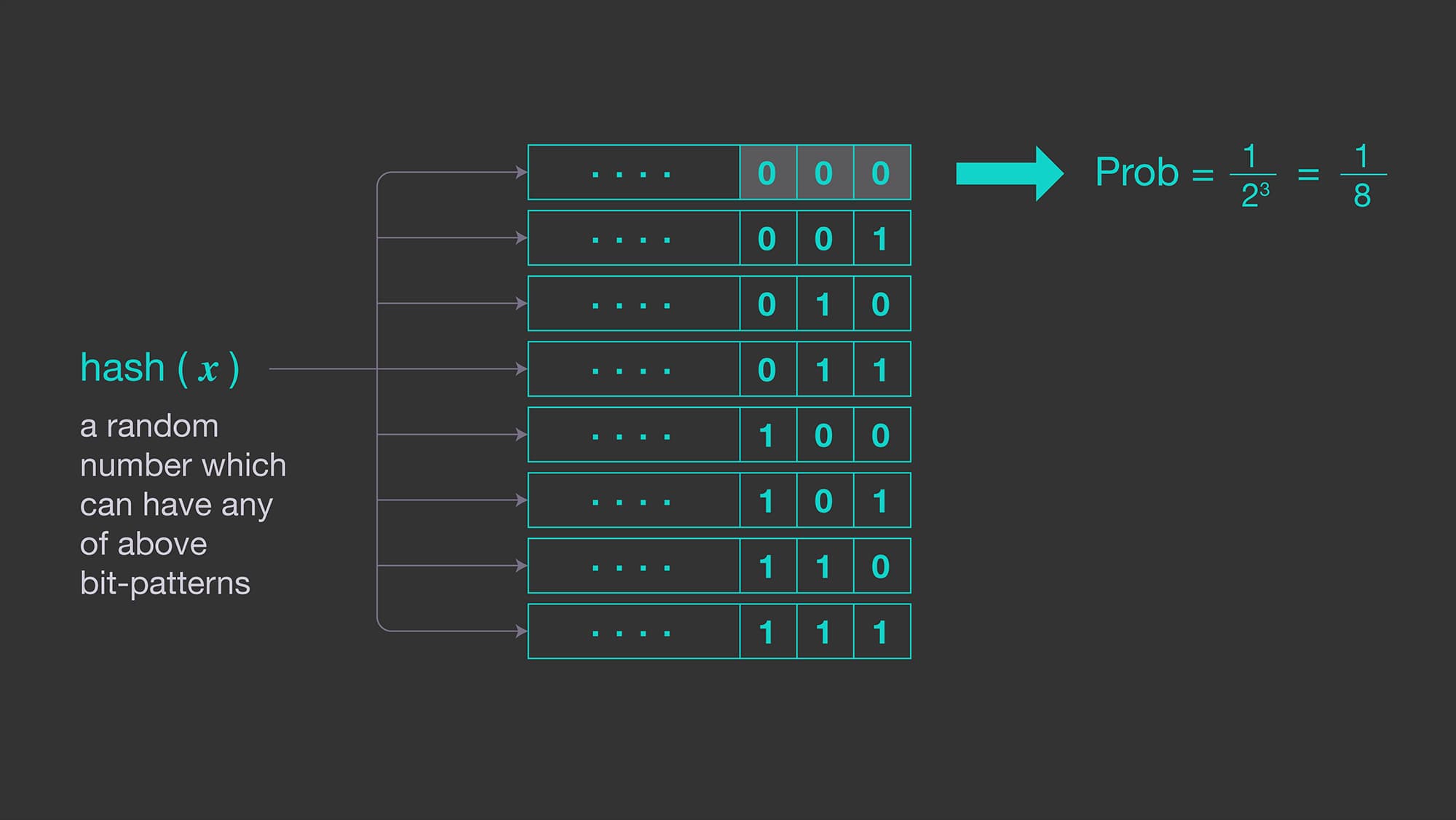
If you've seen a hash with k leading zeros, you've observed an event with probability 2^(-k). To have observed it, you likely processed at least 2^k items. If the maximum leading zeros observed is 15, your estimate is that roughly 2^15 = 32,768 distinct items were processed.
Problem: high variance. You might see a hash with 15 leading zeros after processing only 100 distinct items, just by chance.
Multiple registers (the HLL improvement)
HyperLogLog reduces variance by splitting the input stream into multiple sub-streams using the first few bits of the hash, and tracking the maximum leading zeros in each sub-stream independently. It then takes the harmonic mean of the 2^b sub-stream estimates (where b bits are used for sub-stream selection).
Hash: 0b 0010 | 11010...
↑ ↑
sub-stream ID remaining bits (used for max-zeros calculation)
(first 4 bits → sub-stream 2)
With b=14 (16,384 sub-streams), each register holds a 6-bit counter (the max leading zeros for that sub-stream). Total memory: 16,384 × 6 bits = ~12KB. Redis's HLL uses this configuration.
Harmonic mean: taking the harmonic mean of the sub-stream estimates reduces the impact of outliers (a single sub-stream that gets a very high leading-zero count due to chance).
Error rate
Standard error ≈ 1.04 / √(number of registers)
With 16,384 registers: 1.04 / √16,384 ≈ 0.81% standard error. Redis guarantees < 2% standard error in practice across all cardinalities.
This means: if your link has exactly 1,000,000 unique visitors, the HLL estimate is somewhere in the range 980,000–1,020,000 (99% of the time). For a "unique visitors" metric on an analytics dashboard, this is indistinguishable from exact.
HyperLogLog in Redis
Redis has native HyperLogLog support:
# Add IP addresses to the HLL for a link
PFADD hll:link:x7Kp2:2025-06-01 "203.0.113.42"
PFADD hll:link:x7Kp2:2025-06-01 "198.51.100.7"
PFADD hll:link:x7Kp2:2025-06-01 "203.0.113.42" # duplicate — HLL handles it
# Get the estimated count of distinct items
PFCOUNT hll:link:x7Kp2:2025-06-01
# → 2 (two distinct IP addresses)
# Merge multiple HLLs (count distinct across multiple links or time periods)
PFMERGE hll:user:123:2025-06-01 hll:link:x7Kp2:2025-06-01 hll:link:aB3cD:2025-06-01
PFCOUNT hll:user:123:2025-06-01
# → estimated unique visitors across both links combined
Memory: Redis's HyperLogLog uses at most 12KB per key, regardless of how many distinct items are added. Compare this to a Redis Set which grows linearly — 12KB for 300 items at ~40 bytes/item.
PFMERGE: HLLs can be merged (union) to estimate cardinality across multiple sub-sets. This makes it easy to compute "total unique visitors across all of a user's links" without querying individual link sets.
Other systems using HyperLogLog
Google BigQuery: APPROX_COUNT_DISTINCT(column) uses HyperLogLog internally. Runs in seconds on tables with billions of rows; exact COUNT(DISTINCT column) requires full table scans and is much slower.
PostgreSQL: the hll extension (from Aggregate Knowledge / Citus) adds HLL data types for streaming cardinality estimation.
Apache Spark / Flink: approxCountDistinct and approx_count_distinct functions in streaming and batch analytics.
Apache Cassandra: HLL support via UDAFs (user-defined aggregate functions) for approximate cardinality in time series workloads.
HLL vs Bloom filter: different questions
| Bloom Filter | HyperLogLog | |
|---|---|---|
| Question answered | "Have I seen X before?" | "How many distinct items have I seen?" |
| Output | Yes/No (with false positive risk) | Count estimate |
| Use case | Membership testing (deduplication) | Cardinality estimation (unique counts) |
| Memory | ~10 bits per item (1% FPR) | Fixed ~12KB regardless of cardinality |
| Supports removal | No (standard) | No |
For unique click tracking:
- Bloom filter: "has IP 203.0.113.42 already clicked link x7Kp2 today?" — deduplication (should I count this as a unique click?)
- HyperLogLog: "how many distinct IPs clicked link x7Kp2 today?" — reporting (what number do I show on the dashboard?)
The URL shortener can use both: Bloom filter to deduplicate click events in real time (post 08), HyperLogLog to store the running unique-visitor count efficiently for dashboard display.
Tradeoffs
Approximate, not exact. <2% error is excellent for analytics but unacceptable for billing, compliance, or any use case where exact counts matter.
No retrieval. Like Bloom filters, HLLs don't store the individual items — you can get the count estimate, but not the list of items.
No deletion. Once an item is added to an HLL, it cannot be removed (without rebuilding the structure).
Merge-friendly. HLLs support union (PFMERGE) — you can compute the distinct count across the union of multiple sets without a full set union operation. This is a powerful property for aggregating across time windows, user groups, or other dimensions.
The one thing to remember
HyperLogLog counts distinct items in constant memory (~12KB) with less than 2% error, regardless of whether you're counting a hundred items or a billion. For analytics workloads — unique visitors, distinct users, distinct query patterns — this is almost always the right tool: exact counting requires O(n) memory; HLL provides a practical approximation at constant cost. Redis's
PFADD/PFCOUNT/PFMERGEimplement it natively, making it the lowest-friction way to add approximate distinct counting to any system already using Redis.
← Previous: Bloom Filter — a probabilistic data structure that answers "have I seen this?" in constant memory, with no false negatives.
→ Next: Wrap-up — tying together all nine concepts in this pillar and building toward Pillar 7: Architecture Patterns.




