The Circuit Breaker: Stopping Cascading Failures
Series: System Design · Architecture Patterns — Pillar 7 of 8
Systems Design
| # | Post | What it covers |
|---|---|---|
| 00 | Architecture Patterns: How Systems Are Structured | Twenty patterns covering monoliths, microservices, events, resilience, deployment, and data processing. How to structure systems that survive growth. |
| 01 | Monolithic Architecture: The Default That Gets Abandoned Too Early | Monoliths are fast to build and easy to operate. Learn when they're the right choice, when they break down, and how to know the difference. |
| 02 | Microservices: The Architecture You Earn, Not Choose | Microservices enable independent scaling and team autonomy — but at significant cost. Learn what you actually get, what you pay, and when it's worth it. |
| 03 | Serverless: Pay for What You Use, Not What You Provision | Serverless scales to zero and charges per invocation. Learn where it shines, where it fails, and how to design around cold starts and vendor lock-in. |
| 04 | Event-Driven Architecture: Decoupling Through Events | Event-driven systems communicate via events rather than direct calls. Learn how producers, consumers, and event brokers work — and the consistency tradeoffs involved. |
| 05 | Message Queues: Decoupling Produce from Consume | Message queues decouple producers and consumers, enable load levelling, and provide durability. Learn how they work and when to use Kafka vs SQS vs RabbitMQ. |
| 06 | Pub/Sub: Broadcasting Events to Multiple Consumers | Pub/sub decouples publishers from subscribers through topics. Learn how it differs from message queues and when to use Kafka, SNS, or Google Pub/Sub. |
| 07 | CQRS: When Reads and Writes Need Different Models | CQRS separates writes from reads so each can be optimised independently. Learn how it works, when it's worth the complexity, and when it isn't. |
| 08 | Event Sourcing: The Ledger, Not the Balance | Event sourcing stores state as a sequence of events. Learn how it works, what you get (audit log, time travel), and what it costs (complexity, schema evolution). |
| 09 | The Saga Pattern: Distributed Transactions Without Locks | The Saga pattern manages distributed transactions across services using compensating transactions. Learn choreography vs orchestration and when to use each. |
| 10 | The Outbox Pattern: Atomic Writes and Event Publishing | The Outbox pattern solves the dual-write problem — publishing an event and writing to a database atomically. Learn how it works using CDC or polling. |
| 11 | The Circuit Breaker: Stopping Cascading Failures ← you are here | Circuit breakers prevent cascading failures by fast-failing calls to unhealthy dependencies. Learn the three states, how to configure them, and where to apply them. |
| 12 | The Bulkhead Pattern: Containing Failures Through Resource Isolation | Bulkheads isolate thread pools and connections per dependency so one failure can't exhaust resources needed by others. Learn how to apply them in practice. |
| 13 | The Sidecar Pattern: Cross-Cutting Concerns Without Code Changes | The sidecar pattern deploys a helper process alongside each service for logging, metrics, TLS, and service discovery — without modifying the service itself. |
| 14 | Service Mesh: A Programmable Network for Microservices | A service mesh handles service-to-service traffic, mTLS, circuit breaking, and observability via a fleet of sidecar proxies. Learn how it works and when to use it. |
| 15 | Service Discovery: Finding Services in a Dynamic Environment | Service discovery lets services find each other in dynamic environments. Learn client-side vs server-side discovery, health checks, and DNS vs registry approaches. |
| 16 | The Strangler Fig: Replacing a Legacy System Without Burning It Down | The Strangler Fig replaces a legacy system incrementally by routing specific functionality to new implementations while the old system keeps running. |
| 17 | Backend for Frontend: One API Per Client Type | BFF creates dedicated API backends per client type. Learn why one general API struggles to serve mobile and web well, and how BFF solves it. |
| 18 | ETL Pipelines: Moving Data from Operations to Analytics | ETL moves data from operational systems into analytical stores. Learn how pipelines work, what ELT is, and how to design reliable data movement at scale. |
| 19 | Batch vs Stream Processing: How Fresh Do Your Answers Need to Be? | Batch processes accumulate data then processes in bulk; streaming processes each event as it arrives. Learn the tradeoffs and when each is right. |
| 20 | MapReduce: Processing Petabytes in Parallel | MapReduce processes massive datasets in parallel by splitting work into map and reduce phases. Learn how it works and why Spark has largely replaced it. |
| 21 | Architecture Patterns: Wrap-Up | A recap of all 20 architecture patterns across decomposition, async communication, data patterns, resilience, and data processing. How they connect. |
The Circuit Breaker: Stopping Cascading Failures
The problem
Your URL shortener's redirect service calls an analytics service to record every click event. On a normal day, this call takes 2ms. Then the analytics service develops a memory leak. It starts responding slowly — 200ms, then 1000ms, then timing out entirely.
Your redirect service has a 5-second timeout per call. While waiting for the analytics service to respond (or time out), every redirect handler is holding a thread. With 10,000 concurrent redirects and 5-second timeouts, you're accumulating 10,000 blocked threads in seconds. Thread pool exhausts. The redirect service — which was working perfectly — starts rejecting all requests because it has no threads left to handle them.
A failure in one non-critical service has cascaded into a failure of the critical redirect service. The analytics service dragged the redirect service down with it.
The core idea
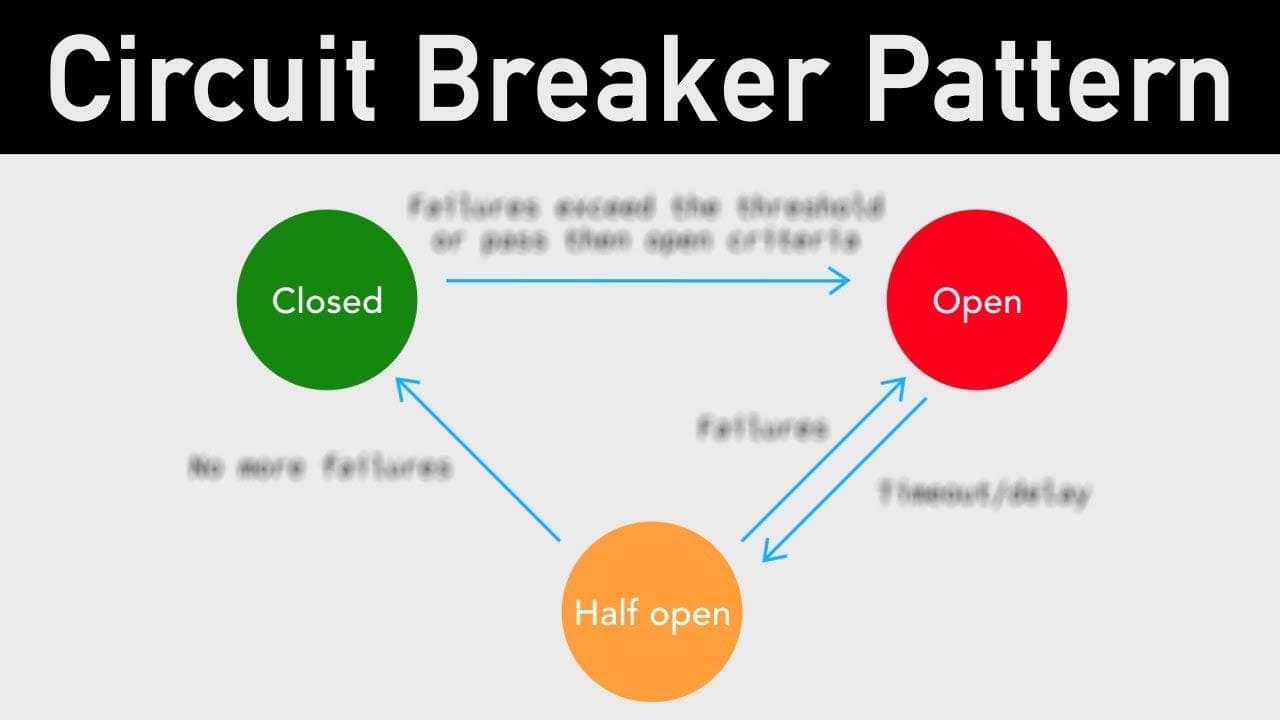
A circuit breaker wraps calls to an external dependency. When the dependency starts failing (errors or timeouts exceed a threshold), the circuit "opens" — subsequent calls are rejected immediately without attempting the dependency, returning a fallback or error instantly. After a cooldown period, the circuit enters "half-open" state and lets a small number of test calls through. If they succeed, the circuit closes and normal operation resumes.
The analogy: an electrical circuit breaker
An electrical circuit breaker trips when current exceeds a safe threshold — overheating, shorts, or faults. Once tripped, it cuts power immediately to prevent further damage. An electrician investigates, fixes the problem, and manually resets the breaker. Once reset, power flows again.
The software circuit breaker works the same way:
The breaker "trips" (opens) when failure rate exceeds a threshold
Subsequent requests are "cut" immediately (no waiting for timeouts)
After a cooldown, the breaker auto-resets (half-open) and tests whether the dependency recovered
If tests pass, the circuit closes and normal operation resumes
The three states
Closed (normal operation)
Requests pass through to the dependency. The circuit breaker monitors the success/failure rate in a rolling window. Below the failure threshold: stay closed.
Open (failing dependency)
The failure rate exceeded the threshold. All subsequent requests to this dependency are rejected immediately with a fallback response — no actual call is made. The thread is never blocked waiting for a timeout.
Requests → Circuit Breaker (OPEN)
→ Immediate rejection (no call to analytics service)
→ Returns fallback: {} or null or throws CircuitOpenException
→ Request completes in microseconds, not seconds
The timeout to the dependency no longer affects the caller's latency. Thread pool is not exhausted. The redirect service stays healthy.
Half-Open (testing recovery)
After a configurable cooldown period (e.g., 30 seconds), the circuit enters half-open. A small number of requests (e.g., 5) are allowed through to test whether the dependency has recovered.
All 5 succeed → circuit closes (resume normal operation)
Any of the 5 fail → circuit opens again (cooldown restarts)
Open state fast-fail comparison — before/after layout.
Left side shows threads piling up in the redirect service waiting on the 5-second analytics timeout, pool exhausting, cascade failure. Right side shows the circuit open, redirect service threads healthy, the CB returning a fallback in ~1ms. The proportional latency bars at the bottom make the difference visceral.
Implementation
Hystrix (Java, Netflix OSS, now legacy) / Resilience4j (Java)
// Resilience4j circuit breaker
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // open if 50%+ of calls fail
.waitDurationInOpenState(Duration.ofSeconds(30))
.permittedNumberOfCallsInHalfOpenState(5)
.slidingWindowSize(20) // measure over last 20 calls
.build();
CircuitBreaker cb = CircuitBreaker.of("analytics", config);
Try<Void> result = cb.executeSupplier(() -> analyticsService.recordClick(event))
.recover(CallNotPermittedException.class, ex -> null); // fallback
In a service mesh (Envoy / Istio)
Circuit breaking can be configured at the infrastructure layer — no application code changes required:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: analytics-service
spec:
host: analytics-service
trafficPolicy:
outlierDetection:
consecutiveErrors: 5
interval: 30s
baseEjectionTime: 30s
Envoy's "outlier detection" ejects unhealthy upstream hosts from the load balancing pool — a circuit breaker at the proxy level.
Fallback strategies
A circuit that's open must do something. Options, in order of preference:
Cached response: return the last known good value from a local cache. The redirect service can cache click event writes locally and flush when analytics recovers.
Default / degraded response: return a sensible default. If analytics is down, record the redirect but skip the click event (lose the data point, preserve the core function).
Fail fast with informative error: return an error to the caller that indicates the downstream dependency is unavailable — not a generic 500. The caller can decide how to handle it.
Queue for retry: if losing the data is unacceptable, write to a local buffer and flush when the dependency recovers. Risky if the dependency is down for a long time (buffer fills), but preserves data for brief outages.
Tradeoffs
Protection vs data loss. An open circuit saves the calling service from exhausting its resources — but it may mean some operations are skipped (analytics events not recorded, notifications not sent). The circuit breaker protects availability at the cost of completeness. Fallback strategies mitigate this.
Configuration sensitivity. A circuit breaker with a very low threshold opens on transient blips. Too high and it takes too long to trip when there's a real failure. Tune thresholds based on your dependency's historical error rate and the cost of false trips.
Visibility. Calls that fail silently behind a circuit breaker don't appear as errors in the caller's metrics — they appear as fast successes (the fallback returned). You need explicit circuit breaker state metrics (open/closed, rejection rate) to know when a dependency is degraded.
The one thing to remember
A circuit breaker prevents a slow or failing dependency from exhausting the resources of its caller. Without one, slow dependencies cause threads to pile up behind timeouts, eventually taking down the calling service entirely — a cascade failure. With a circuit breaker, failures are fast and bounded: callers get an immediate rejection and execute a fallback rather than waiting for a timeout and eventually running out of capacity. In a microservices system, circuit breakers on all external dependencies are not optional.
← Previous: Outbox Pattern — ensuring that a database write and a message publish happen atomically, solving the "dual-write" problem that plagues event-driven systems.
→ Next: Bulkhead — isolating resource pools per dependency so one slow service can't starve another.




