Batch vs Stream Processing: How Fresh Do Your Answers Need to Be?
Series: System Design · Architecture Patterns — Pillar 7 of 8
Systems Design
| # | Post | What it covers |
|---|---|---|
| 00 | Architecture Patterns: How Systems Are Structured | Twenty patterns covering monoliths, microservices, events, resilience, deployment, and data processing. How to structure systems that survive growth. |
| 01 | Monolithic Architecture: The Default That Gets Abandoned Too Early | Monoliths are fast to build and easy to operate. Learn when they're the right choice, when they break down, and how to know the difference. |
| 02 | Microservices: The Architecture You Earn, Not Choose | Microservices enable independent scaling and team autonomy — but at significant cost. Learn what you actually get, what you pay, and when it's worth it. |
| 03 | Serverless: Pay for What You Use, Not What You Provision | Serverless scales to zero and charges per invocation. Learn where it shines, where it fails, and how to design around cold starts and vendor lock-in. |
| 04 | Event-Driven Architecture: Decoupling Through Events | Event-driven systems communicate via events rather than direct calls. Learn how producers, consumers, and event brokers work — and the consistency tradeoffs involved. |
| 05 | Message Queues: Decoupling Produce from Consume | Message queues decouple producers and consumers, enable load levelling, and provide durability. Learn how they work and when to use Kafka vs SQS vs RabbitMQ. |
| 06 | Pub/Sub: Broadcasting Events to Multiple Consumers | Pub/sub decouples publishers from subscribers through topics. Learn how it differs from message queues and when to use Kafka, SNS, or Google Pub/Sub. |
| 07 | CQRS: When Reads and Writes Need Different Models | CQRS separates writes from reads so each can be optimised independently. Learn how it works, when it's worth the complexity, and when it isn't. |
| 08 | Event Sourcing: The Ledger, Not the Balance | Event sourcing stores state as a sequence of events. Learn how it works, what you get (audit log, time travel), and what it costs (complexity, schema evolution). |
| 09 | The Saga Pattern: Distributed Transactions Without Locks | The Saga pattern manages distributed transactions across services using compensating transactions. Learn choreography vs orchestration and when to use each. |
| 10 | The Outbox Pattern: Atomic Writes and Event Publishing | The Outbox pattern solves the dual-write problem — publishing an event and writing to a database atomically. Learn how it works using CDC or polling. |
| 11 | The Circuit Breaker: Stopping Cascading Failures | Circuit breakers prevent cascading failures by fast-failing calls to unhealthy dependencies. Learn the three states, how to configure them, and where to apply them. |
| 12 | The Bulkhead Pattern: Containing Failures Through Resource Isolation | Bulkheads isolate thread pools and connections per dependency so one failure can't exhaust resources needed by others. Learn how to apply them in practice. |
| 13 | The Sidecar Pattern: Cross-Cutting Concerns Without Code Changes | The sidecar pattern deploys a helper process alongside each service for logging, metrics, TLS, and service discovery — without modifying the service itself. |
| 14 | Service Mesh: A Programmable Network for Microservices | A service mesh handles service-to-service traffic, mTLS, circuit breaking, and observability via a fleet of sidecar proxies. Learn how it works and when to use it. |
| 15 | Service Discovery: Finding Services in a Dynamic Environment | Service discovery lets services find each other in dynamic environments. Learn client-side vs server-side discovery, health checks, and DNS vs registry approaches. |
| 16 | The Strangler Fig: Replacing a Legacy System Without Burning It Down | The Strangler Fig replaces a legacy system incrementally by routing specific functionality to new implementations while the old system keeps running. |
| 17 | Backend for Frontend: One API Per Client Type | BFF creates dedicated API backends per client type. Learn why one general API struggles to serve mobile and web well, and how BFF solves it. |
| 18 | ETL Pipelines: Moving Data from Operations to Analytics | ETL moves data from operational systems into analytical stores. Learn how pipelines work, what ELT is, and how to design reliable data movement at scale. |
| 19 | Batch vs Stream Processing: How Fresh Do Your Answers Need to Be? ← you are here | Batch processes accumulate data then processes in bulk; streaming processes each event as it arrives. Learn the tradeoffs and when each is right. |
| 20 | MapReduce: Processing Petabytes in Parallel | MapReduce processes massive datasets in parallel by splitting work into map and reduce phases. Learn how it works and why Spark has largely replaced it. |
| 21 | Architecture Patterns: Wrap-Up | A recap of all 20 architecture patterns across decomposition, async communication, data patterns, resilience, and data processing. How they connect. |
Batch vs Stream Processing: How Fresh Do Your Answers Need to Be?
The problem
Your URL shortener's analytics pipeline receives fifty thousand click events per second. Several downstream computations need to happen:
Real-time fraud detection: is this IP address sending clicks at an anomalous rate right now? Must be answered in milliseconds.
Per-link click counters: update the counter for the link's stats dashboard. Acceptable within 1 second.
Daily analytics digest emails: summarise each user's link performance from yesterday. Acceptable with 1-day lag.
Monthly billing calculations: compute each account's click volume for invoice generation. Runs once a month.
These four requirements have wildly different freshness needs. Using stream processing for monthly billing (over-engineered) or batch processing for fraud detection (too slow) are both wrong. The architecture must match each requirement's latency tolerance.
The core idea
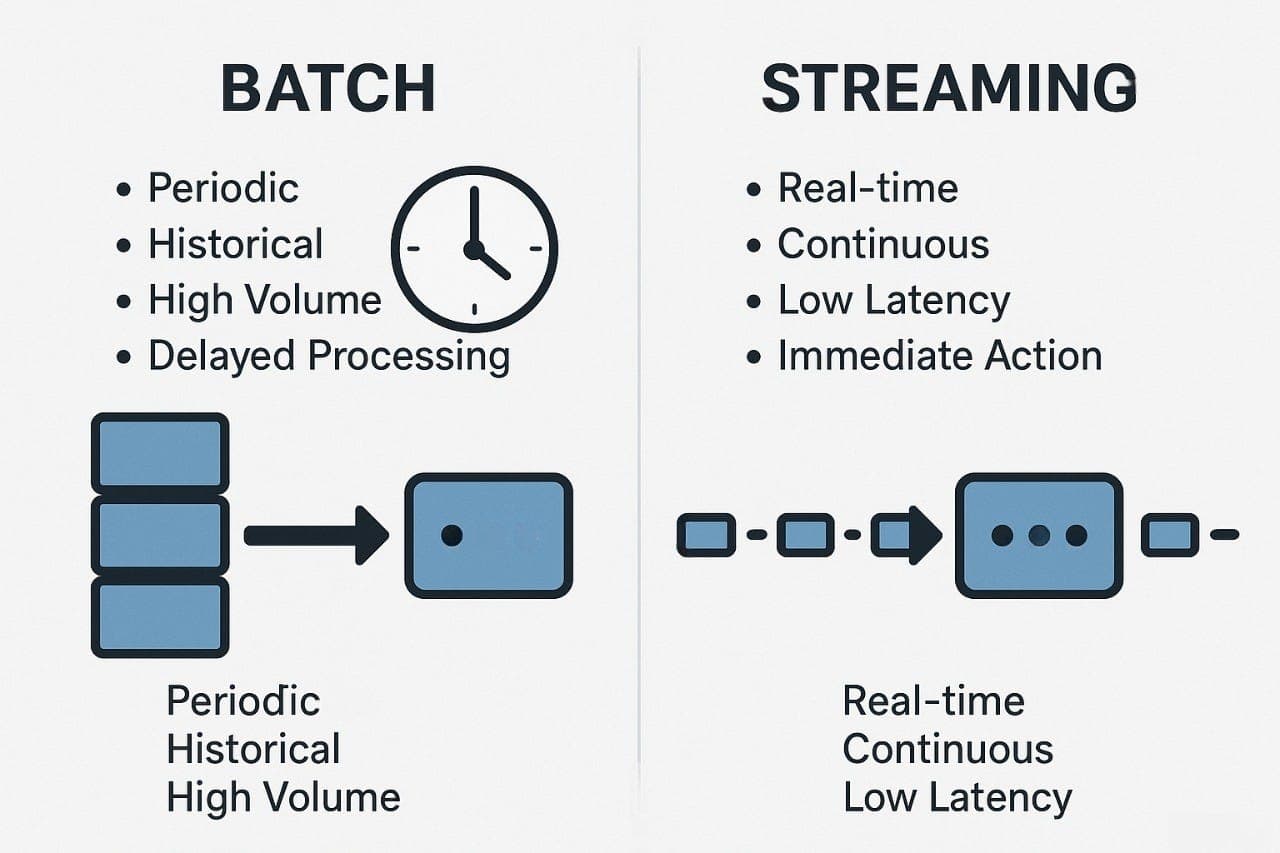
Batch processing accumulates a dataset and processes it in one bulk operation — nightly, hourly, or triggered by a schedule. High throughput per job; inherent latency equal to the batch interval.
Stream processing processes each event as it arrives — continuously, with results available seconds or milliseconds after events occur. Low latency; requires always-on infrastructure.
The choice is primarily determined by the acceptable lag between an event occurring and its results being used. Everything else (throughput, complexity, cost) follows from this.
The analogy: postal delivery vs a phone call
Batch processing is postal delivery: letters accumulate over a day, are sorted at a central facility, and delivered in bulk the next morning. High throughput per delivery trip; inherent overnight latency.
Stream processing is a phone call: the message is transmitted and received in real time. No accumulation; the recipient gets the information instantly. Requires a connection to be active continuously.
Most communications don't need to be phone calls. A birthday card doesn't need real-time delivery. But a fire alarm does. Know which is which.
Batch processing
How it works
Data is frozen at the batch boundary (midnight). The analytics digest email reflects yesterday's complete data with no ambiguity about what "yesterday" means.
Batch processing frameworks
Apache Spark: distributed batch processing at scale. Reads from HDFS, S3, databases. Applies transformations and aggregations in parallel across a cluster. Returns results when the job completes.
dbt: runs SQL-based transformations against a data warehouse on a schedule. Not a distributed compute framework — the data warehouse does the compute — but provides the scheduling, lineage, and testing framework.
Airflow (Apache) / Prefect / Dagster: workflow orchestrators that schedule and manage batch jobs, handle dependencies between jobs (job B runs only after job A completes), alert on failures.
Strengths
Simple to reason about: fixed input, deterministic output, clear job boundaries
High throughput: optimised for bulk reads, bulk writes, bulk transformations
Fault recovery: if a batch job fails, re-run it with the same input
Late data handling: data that arrives late can be included in the next batch
Weaknesses
Inherent latency: results are available no sooner than the batch completes. Hourly batch → at least 1 hour of lag.
Resource spikes: batch jobs consume large amounts of compute at scheduled times. The rest of the time, compute is idle.
Stream processing
How it works
Each event is processed as it arrives, typically within milliseconds to seconds. Results are continuously produced.
Stream processing frameworks
Apache Flink: powerful stream processing framework with exactly-once semantics, event-time processing, and stateful computations. Processes millions of events per second.
Apache Kafka Streams: stream processing library built on Kafka. Simple to run — no separate cluster, runs as part of the application. Good for moderate-throughput stream processing.
Apache Spark Structured Streaming: treats a stream as an unbounded table and processes it with Spark SQL. Micro-batch under the hood (processes small batches every N seconds) — not true event-at-a-time streaming, but latency can be as low as 1 second.
AWS Kinesis Data Analytics / Google Dataflow: managed stream processing services.
Strengths
Low latency: results are available seconds or milliseconds after events arrive
Continuous output: dashboards, counters, alerts can be updated in real time
No accumulation: no waiting for a batch to complete before processing begins
Weaknesses
Infrastructure complexity: requires an always-on stream processing cluster
State management: aggregations over time windows (count clicks in the last 5 minutes) require managing state across potentially millions of keys
Late data handling: events that arrive out of order or late require watermark logic to decide when to finalize a window's result
Higher operational cost: running a Flink cluster 24/7 is more expensive than running a batch job once per hour
The Lambda Architecture
Many systems need both: low-latency results for dashboards, and high-accuracy batch results for billing and reporting. The Lambda Architecture runs both simultaneously:
The stream layer provides freshness; the batch layer provides correctness. The query layer serves the most appropriate result depending on the time window requested.
In practice, stream processing frameworks have matured enough that Lambda Architecture is less necessary — Flink with exactly-once semantics and event-time processing can produce results as accurate as batch. But the two-tier pattern remains useful when the stream layer is eventually consistent and the batch layer is the source of truth.
Decision framework
Also consider:
Does the computation require joining against a full historical dataset? → batch (or materialized views)
Is the computation stateful (count distinct users in a rolling 24h window)? → stream with state management
Does billing depend on exact accuracy with late-data handling? → batch (stream can miss late-arriving data)
The one thing to remember
Batch processing is simpler, cheaper, and more accurate for historical data; stream processing provides low latency at higher operational complexity. The decision is driven entirely by how fresh the results must be. Don't build a streaming pipeline for a use case that can tolerate an hourly batch run — the operational overhead isn't worth it. Don't use a nightly batch for fraud detection — the latency is the vulnerability. Match the processing model to the freshness requirement.
← Previous: ETL Pipelines — moving data from operational systems into analytical stores, transforming it for the queries analysts and data scientists actually run.
→ Next: MapReduce — the programming model behind batch processing at scale; how massive datasets are processed in parallel across hundreds of machines.




